一篇RBO的优化器论文(1997)
Content
头图来源:2.14-荻pote-#pixiv
Intro
该篇论文的提出有以下几个背景:
- 在复杂的应用环境中(如决策支持系统等),一个查询请求往往同时包含了大量的子查询和视图(view),每个子查询和视图在查询图中组成为一个block,大多数CBO同一时间只能处理一个block,因此如果能够将大多数单独的block合并成一个block则能大大提升优化器的执行效率,而如果当查询中包含了聚合函数、关联查询的话这又将成为一项艰巨且近乎不可能完成的任务。这边我理解为聚合函数和关联查询需要依赖于Group by和Subquery的结果,因此无法简单地与其他block进行合并
- 传统的谓词下移方法(Predict Push Down)仅适用于层级查询,无法用于递归查询递归查询是通过CTE(表表达式)来实现。至少包含两个查询,第一个查询为定点成员,定点成员只是一个返回有效表的查询,用于递归的基础或定位点;第二个查询被称为递归成员,使该查询称为递归成员的是对CTE名称的递归引用是触发。在逻辑上可以将CTE名称的内部应用理解为前一个查询的结果集。
什么是Predict Move-Around
Predict Move-Around(以下简称PMA)顾名思义就是通过将谓词进行移动(Pull Up or Push Down)尽可能地再查询早期筛掉大部分数据已达成优化的目的。
论文给出了一个例子:假设有如下五张表
1.calls(FromAC, FromTel,ToAC, ToTel, AccessCode,StartTime, Length)
2.customers(AC, Tel, OwnerName,Type, MemLevel)
3.users(AC, Tel, UserName,AccessCode)
4.secret(AC, Tel)
5.promotion(AC, SponsorName, StartingDate, EndingDate)其中{AC,Tel}为customers表的主键
有查询Q1如下
(Q1):SELECT ptc.AC, ptc.Tel, PgUserName, p.SponsorName
FROM ptCustomers ptc, fgAccounts fg, promotion p
WHERE ptc.AC = fg.AC AND
ptc.Tel = fg.Tel AND
ptc.MaxLen > 50 AND
p.AC = ptc.ToAC其中ptCustomers和fgAccounts分别为两个视图
(E1):CREATE VIEW fgAccounts(AC,Tel,UserName) AS
SELECT DISTINCT c.AC,c.Tel,u.UserName
FROM customers c,users u
WHERE c.AC = u.AC AND
c.Tel = u.Tel AND
c.Type = "Govt" AND
c.AC = "011" AND
NOT EXISTS(SELECT * FROM secret s
WHERE s.AC = c.AC AND s.Tel = c.Tel)
(F1):CREATE VIEW ptCustomers(AC,Tel,OwnerName,ToAC,MaxLen) AS
SELECT c.AC,c.Tel,c.OwnerName,t.ToAC,MAX(t.Length)
FROM customers c, calls t
WHERE t.Length > 2 AND
t.FromAC <> t.ToAC AND
c.AC = t.FromAC AND
c.Tel = t.FromTel AND
c.MemLevel = "Silver"
GROUP BY c.AC,c.Tel,c.OwnerName,t.ToAC对于查询Q1可以有几项优化方案
- 将谓词
c.AC = "011"移动到ptCustomers,ptCustomers的condition将变成t.FromAC = "011" AND t.ToAC <> "011"。将这些谓词Push Down即可筛掉customers表的数据简化join。 - 将谓词
c.Type = "Govt"移动到ptCustomers,为什么这样做是正确的呢?因为ptCustomers和fgAccounts中以customers的键{AC,Tel}作为join条件,因此除了主键外任意attribute在两视图中的任一个被限定就可以将此限定条件移动到另一个视图中。类似地,可以将ptCustomers中的c.MemLevel = "Silver"移动到fgAccounts中(这一步骤优化器需要知道customers的依赖关系)。 - 将谓词
NOT EXISTS(...)移动到ptCustomers,这样做的目的是筛掉更多customers中的数据,这样在执行join和GROUP BY的时候能更有效率。(然而这样ptCustomers不是又多了一个子查询吗?多出来的子查询是否一定能给原来的查询带来更高的执行效率?) - 把
ptCustomers中的t.Length > 2替换成Q1中的MaxLen > 50。反正最后只要大于50的,2<t.Length<=50这部分的数据都是不需要的,不如趁早把大于50的数据筛出来。
Query Tree
PMA把查询执行逻辑抽象成一颗查询树,这颗查询树由一个个block组成,而block又由一个个node组成。
Local and Exported Attributes
这边有两个概念:
- Local Attributes:位于其所在block中的操作数之中,比如
WHERE c.AC = xx中的AC,即原表schema中的attribute。 - Exported Attributes:位于输出结果block中的attribute,比如
CREATE VIEW XXX(A1,A2,A3)...中的Ai。
Labels
在查询树中每个节点都有一个与之相联系的标签,表示为L(n),标签包含了属性n的谓词信息。
Node
文中介绍了三种节点,分别对应于SELECT,GROUPBY和UNION&INTERSECTION三种操作。

Renamings
由于view的shema常常与原表的schema不同,而exported attribute都是来自于local attribute。因此,要让optimizer能移动谓词,需要在两种attribute间做mapping,而这个过程也被称作Renamings。
- internal renaming:将local attribute映射为exported attribute。
- external renaming:将exported attribute映射为local attribute。
算法步骤
该算法主要的分为五部(包含一步optional),以下分别对它们做介绍。
1.Label Initiallization
标签初始化
- SELECT Nodes:初始标签由
WHERE中所包含的谓词构成。 - GROUPBY Triplets:底层node的标签由
WHERE中的谓词构成,顶层node的标签由HAVING中的谓词构成。 - UNION&INTERSECTION Nodes:标签初始化为空。
- Functional Dependencies:假设关系R中存在依赖
fd:{A1,...,Ak}->{B1,...,Bp},如果在WHERE或HAVING中包含关系R,则将Bi=f(r.A1,...,r.Ak)添加到标签中。
2.Predicate Pullup
Predicate Pullup阶段将自底向上遍历查询树,并通过internal renaming将local attribute映射为exported attribute,将谓词附加到节点的父节点。特别地,对于一些特别节点和谓词还将有附加的谓词用于进一步优化查询:
(1)Predicate pullup through SELECT nodes
设有一个SELECT节点n并拥有标签L(n):
- 在对谓词进行移动前可以通过逻辑关系计算
L(n)的闭包,例如现有两个谓词r1.A<r2.B和r2.B<r3.c,则可将r1.A<r3.c加入到L(n)。 - 将
L(n)中的local attribute对应的exported attribute也加入到其中,同时也将exported attribute对应的local attribute加入到其中。例如谓词fgAccounts.AC = "011"中的fgAccounts.AC,其对应的local attribute为c.AC,在对谓词做处理时我们同样需要将它加入到对应的L(n)。
(2)Predicate pullup through GROUPBY nodes
设有GROUPBY节点n并拥有标签L(n):
- 设
Min(B)是n的一个local attribute,则将Min(B)<=B加入L(n)(Max(B)也可以用同样的方法)。这相当于将聚合函数转化为谓词。 - 另外,
Avg(B)是n的一个属性且B<=c在n的标签L(n)中(其中c为常量),则可以推导出Avg(B)<=c,并将其加入标签中。
(3)Predicate pullup through UNION&INTERSECTION nodes
设有UNION(或INTERSECTION)节点n并拥有标签L(n),设节点n有m个子节点,表示为c1,...,cm。则需要将子节点conjunction predicates中的local attribute转化为对应的export attributes,并将它们Pullup。
3.Predicate Pushdown
与Pullup相反,Pushdown自顶向下遍历查询树,将exported attribute转化为对应的local attribute,同样论文中也分别介绍了SELECT,GROUPBY和UNION&INTERSECTION三种节点的pushdown操作,它们与Pullup类似。
4.Label Minimization
对于减少冗余谓词,文中提供了两种方法:
- pullup(或pushdown)操作会造成一些谓词出现在节点及其父节点(甚至祖先节点)中。如果谓词在子代节点中已经被运用,则无需再重复运用。
- 在将谓词加入到标签中先判断标签中是否已经有与此谓词作用相同的谓词,如果存在则直接pass。
5.Translating the Query Tree to SQL
将查询树翻译为SQL,文中给出了对查询Q1的优化结果
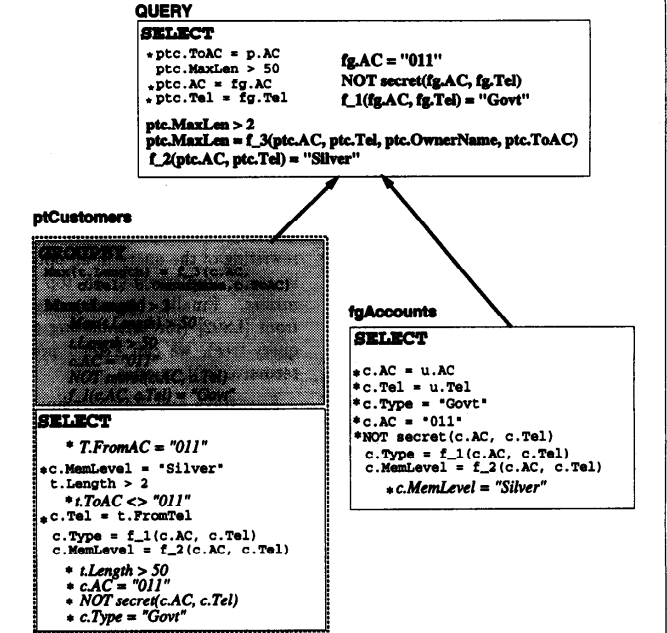
6.Translating DAG Queries
翻译DAG查询:一颗DAG查询树通常由一些关联了相同视图的子查询树构成,这些子树在算法执行之初是相同的,而可能在算法执行之后就会变得不同,而如果在算法执行之后如果两颗子树仍然相同(它们拥有相同标签的情况下,则执行算法后它们将依然相同)则需要选二者其一执行即可。假定T2包含T1,则T2的视图也可在T1视图基础上加上额外的selection计算得出。(这部分其实理解得并不是很清楚,文中也没有给出例子。避免误导还是po上原文吧)
If at the end of the algorithm, T1 and T2 are equivalent (i.e., they have logically equivalent labels in corresponding nodes), then it is sufficient to evaluate just one of T1 and T2. If T1 is contained in T2, then the view for T2 may be computed from the view for T1 by applying an additional selection.If neither one is contained in the other, it may still be possible to compute one view from which the two views can be obtained by additional selections.
